Transformers: The Architecture That Changed Everything
Tutorial Overview
This comprehensive guide explores the revolutionary Transformer architecture, from its historical context to cutting-edge implementations. Perfect for researchers, practitioners, and students seeking deep understanding of modern NLP foundations.
Table of Contents
🔬 Foundations
🏗️ Architectures
⚡ Advanced Topics
Evolution of Sequence Models: From RNNs to Transformers
Attention Mechanisms
1. Additive Attention (Bahdanau et al., 2014)
Reference:
Neural Machine Translation by Jointly Learning to Align and Translate — Bahdanau, Cho, Bengio (2014)
Motivation:
Early encoder–decoder RNNs encoded the entire source sentence into a single fixed-length vector, which made it difficult to handle long sequences. Bahdanau attention lets the decoder “look back” at all encoder states and focus on relevant parts when generating each output token.
Mechanism: At decoding step \( t \):
-
Score function (additive form): $$ e_{t,i} = v_a^\top \tanh(W_a s_{t-1} + U_a h_i) $$
- \( s_{t-1} \): decoder hidden state at previous step
- \( h_i \): encoder hidden state at position \( i \)
- \( W_a, U_a, v_a \): learned parameters
-
Attention weights: $$ \alpha_{t,i} = \frac{\exp(e_{t,i})}{\sum_{k=1}^n \exp(e_{t,k})} $$
-
Context vector: $$ c_t = \sum_{i=1}^n \alpha_{t,i} h_i $$
-
Combine \( c_t \) with decoder state to predict next token.
Key traits:
- Uses a small feed-forward network to compute scores (learned similarity function).
- Can capture complex relationships between decoder and encoder states.
- More parameters, slightly slower.
2. Multiplicative Attention (Luong et al., 2015)
Reference:
Effective Approaches to Attention-based Neural Machine Translation — Luong, Pham, Manning (2015)
Motivation:
Bahdanau attention works well but is computationally slower. Luong proposed a faster variant using dot products for scoring.
Mechanism: At decoding step \( t \):
-
Score function (multiplicative forms):
-
Dot:
$$ e_{t,i} = s_t^\top h_i $$
-
General: $$ e_{t,i} = s_t^\top W_a h_i $$ where \( W_a \) is learned.
-
Scaled form (Transformer-style): $$ e_{t,i} = \frac{(W_q s_t)^\top (W_k h_i)}{\sqrt{d_k}} $$
-
Attention weights:
\[ \alpha_{t,i} = \mathrm{softmax}_i(e_{t,i}) \] -
Context vector:
$$ c_t = \sum_{i=1}^n \alpha_{t,i} h_i $$
- Combine \( c_t \) with decoder state for output prediction.
Key traits:
- Faster due to matrix-friendly dot products.
- Fewer parameters than additive attention.
- Works especially well for large hidden dimensions.
3. Comparison: Additive vs. Multiplicative
| Aspect | Additive (Bahdanau) | Multiplicative (Luong) |
|---|---|---|
| Score function | MLP + \(\tanh\) over \( s, h \) | Dot product or linear projection |
| Parameters | More (extra weight matrices + vector) | Fewer |
| Speed | Slower (more ops per score) | Faster (uses matrix multiplication) |
| Works well for | Small to medium hidden size | Large hidden size, high-speed needs |
| Introduced in | Bahdanau et al., 2014 | Luong et al., 2015 |
4. Connection to Transformers
Transformers use scaled dot-product attention, which is a form of multiplicative attention:
$$ e_{t,i} = \frac{(W_q s_t)^\top (W_k h_i)}{\sqrt{d_k}} $$ Here:
- \( W_q, W_k \): learned projection matrices for queries and keys
- \( d_k \): key dimension for scaling stability
Key takeaway:
- Additive attention learns its own similarity function via a feed-forward network — more flexible but slower.
- Multiplicative attention relies on dot products — faster and simpler, making it the foundation for modern large-scale attention models like Transformers.
RNNs with Attention
Reference Links:
- Foundational Paper: Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al., 2014)
- Follow-up Research: Effective Approaches to Attention-based Neural Machine Translation (Luong et al., 2015)
- Implementation: OpenNMT Attention Mechanisms
- Visual Guide: Attention Mechanism Visualization
Historical Context: The introduction of attention mechanisms in 2014 marked a pivotal moment in deep learning, solving the information bottleneck problem that plagued sequence-to-sequence models.
Core Innovation: Instead of compressing entire input sequences into fixed-size vectors, attention allows decoders to dynamically access relevant parts of the input at each generation step.
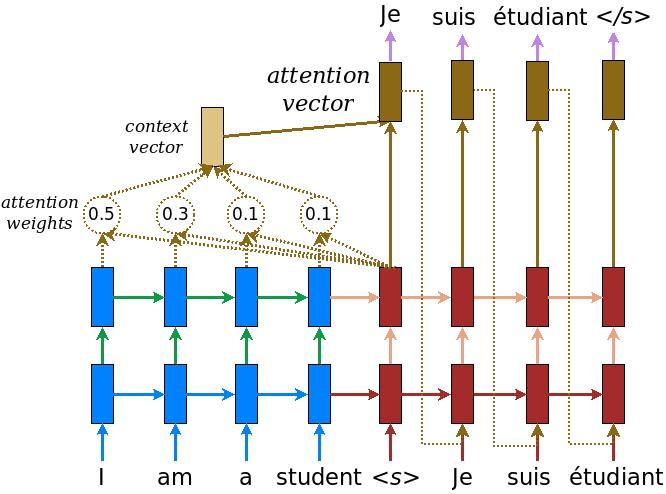 Figure: RNN with Attention Architecture (Source: TensorFlow NMT Tutorial)
Figure: RNN with Attention Architecture (Source: TensorFlow NMT Tutorial)
Research Impact:
- Citation Impact: The Bahdanau paper has over 25,000 citations, establishing attention as a fundamental deep learning concept
- Performance Gains: Attention improved BLEU scores by 5-10 points on translation tasks
- Interpretability: First mechanism to provide interpretable alignment between input and output sequences
Mathematical Foundation:
Additive Attention (Bahdanau):
Multiplicative Attention (Luong):
Implementation Reference: Attention Implementation in PyTorch
Research Evolution:
- 2014: Bahdanau attention introduces learnable alignment
- 2015: Luong attention simplifies with dot-product scoring
- 2016: Google's GNMT scales attention to production systems
- 2017: Transformer architecture eliminates RNNs entirely
Legacy Impact: Attention mechanisms in RNNs laid the groundwork for the Transformer revolution, proving that explicit alignment could replace implicit memory.
The Transformer Revolution
Reference Links:
- Seminal Paper: Attention Is All You Need (Vaswani et al., 2017)
- Original Implementation: Tensor2Tensor Transformer
- Modern Implementation: HuggingFace Transformers
- Interactive Visualization: The Illustrated Transformer
- Research Analysis: The Annotated Transformer
Paradigm Shift: The Transformer architecture fundamentally changed how we think about sequence modeling, proving that attention alone could achieve state-of-the-art results without recurrence or convolution.
 Figure: Complete Transformer Architecture (Source: Tensor2Tensor)
Figure: Complete Transformer Architecture (Source: Tensor2Tensor)
Revolutionary Insights:
- Parallelization: Unlike RNNs, all positions can be processed simultaneously
- Long-range Dependencies: Direct connections between any two positions
- Scalability: Architecture scales efficiently with model size and data
- Transfer Learning: Pre-trained models generalize across diverse tasks
Research Impact:
- Citation Explosion: Over 50,000 citations in 6 years
- Industry Adoption: Powers GPT, BERT, T5, and virtually all modern LLMs
- Performance Leap: Achieved new state-of-the-art across multiple NLP benchmarks
Core Transformer Components
Self-Attention: The Foundation of Modern NLP
Research Foundation:
- Seminal Paper: Attention Is All You Need (Vaswani et al., 2017)
- Theoretical Analysis: What Does BERT Look At? (Clark et al., 2019)
- Efficiency Research: Efficient Transformers: A Survey (Tay et al., 2020)
- Implementation: PyTorch MultiheadAttention
- HuggingFace Implementation: BERT Self-Attention
Conceptual Breakthrough: Self-attention revolutionized sequence modeling by enabling each position to directly attend to all other positions, eliminating the sequential bottleneck of RNNs.
 Figure: Self-Attention Mechanism Visualization (Source: Tensor2Tensor)
Figure: Self-Attention Mechanism Visualization (Source: Tensor2Tensor)
Key Research Insights:
- Attention Patterns: Different heads learn distinct linguistic patterns (syntactic, semantic, positional)
- Layer Specialization: Lower layers focus on syntax, higher layers on semantics
- Interpretability: Attention weights provide insights into model decision-making
- Computational Complexity: \(O(n^2 \cdot d)\) complexity motivates efficiency research
Algorithmic Innovation:
Self-Attention(Q, K, V) = softmax(QK^T / √d_k)V
where Q, K, V = XW_Q, XW_K, XW_V
Mathematical Foundation:
Where:
- \(X \in \mathbb{R}^{n \times d}\): Input sequence matrix
- \(W^Q, W^K, W^V \in \mathbb{R}^{d \times d_k}\): Learned projection matrices
- \(\sqrt{d_k}\): Scaling factor to prevent vanishing gradients
Research Applications:
- Language Models: GPT series, PaLM, LaMDA
- Understanding Tasks: BERT, RoBERTa, DeBERTa
- Multimodal Models: CLIP, DALL-E, Flamingo
- Code Generation: Codex, CodeT5, InCoder
Performance Characteristics:
- Time Complexity: \(O(n^2 d)\) for sequence length \(n\)
- Space Complexity: \(O(n^2 + nd)\) for attention matrix storage
- Parallelization: Fully parallelizable across sequence positions
Multi-Head Attention: Parallel Representation Learning
Research Foundation:
- Core Paper: Attention Is All You Need (Vaswani et al., 2017)
- Head Analysis: Are Sixteen Heads Really Better than One? (Michel et al., 2019)
- Attention Patterns: A Multiscale Visualization of Attention in the Transformer Model (Vig, 2019)
- Implementation: PyTorch MultiheadAttention
- Optimized Implementation: FlashAttention
Core Innovation: Multi-head attention enables the model to simultaneously attend to different types of relationships (syntactic, semantic, positional) by learning multiple attention functions in parallel.
Figure: Multi-Head Attention Architecture (Source: Tensor2Tensor)
Research Discoveries:
- Head Specialization: Different heads learn distinct linguistic phenomena
- Redundancy Analysis: Many heads can be pruned without performance loss
- Attention Distance: Heads exhibit different attention distance patterns
- Layer Hierarchy: Lower layers focus on local patterns, higher layers on global context
Algorithmic Structure:
MultiHead(Q,K,V) = Concat(head₁,...,headₕ)W^O
where headᵢ = Attention(QWᵢ^Q, KWᵢ^K, VWᵢ^V)
Mathematical Formulation:
Parameter Dimensions:
- \(W_i^Q, W_i^K, W_i^V \in \mathbb{R}^{d_{model} \times d_k}\) where \(d_k = d_{model}/h\)
- \(W^O \in \mathbb{R}^{d_{model} \times d_{model}}\): Output projection
- Total parameters: \(4d_{model}^2\) (same as single-head with larger dimensions)
Efficiency Innovations:
- Grouped Query Attention (GQA): Reduces KV cache size in large models
- Multi-Query Attention (MQA): Shares K,V across heads for faster inference
- FlashAttention: Memory-efficient attention computation
- Sparse Attention: Reduces quadratic complexity with structured sparsity
Modern Applications:
- GPT-4: Uses advanced attention patterns for improved reasoning
- PaLM: Scales to 540B parameters with efficient attention
- LLaMA: Optimized attention for research accessibility
Feed-Forward Networks: Non-Linear Transformation
Research Foundation:
- Original Paper: Attention Is All You Need (Vaswani et al., 2017)
- Activation Analysis: GLU Variants Improve Transformer (Shazeer, 2020)
- Scaling Laws: Scaling Laws for Neural Language Models (Kaplan et al., 2020)
- Implementation: HuggingFace FFN
- Modern Variants: SwiGLU Implementation
Core Function: FFNs provide the primary source of non-linearity and parameter capacity in Transformers, typically containing 2/3 of the model's parameters.
Research Evolution:
- ReLU (2017): Original activation function in Transformers
- GELU (2018): Smoother activation, better for language tasks
- SwiGLU (2020): Gated activation, used in modern LLMs (PaLM, LLaMA)
- GeGLU (2020): Variant of GLU with GELU activation
Mathematical Formulations:
Standard FFN:
SwiGLU (Modern LLMs):
Parameter Scaling:
- Standard: \(d_{ff} = 4 \times d_{model}\) (e.g., 3072 for BERT-base)
- Modern LLMs: \(d_{ff} = \frac{8}{3} \times d_{model}\) for SwiGLU variants
Layer Normalization: Training Stabilization
Research Foundation:
- Seminal Paper: Layer Normalization (Ba et al., 2016)
- RMSNorm Innovation: Root Mean Square Layer Normalization (Zhang & Sennrich, 2019)
- Pre/Post-Norm Analysis: On Layer Normalization in the Transformer Architecture (Xiong et al., 2020)
- Implementation: PyTorch LayerNorm
- RMSNorm Implementation: LLaMA RMSNorm
Training Breakthrough: Layer normalization solved the internal covariate shift problem, enabling stable training of deep Transformers without careful initialization.
Normalization Evolution:
- LayerNorm (2016): Normalizes across feature dimension
- RMSNorm (2019): Removes mean centering, used in modern LLMs
- Pre-Norm vs Post-Norm: Placement affects gradient flow and performance
Mathematical Formulations:
Standard LayerNorm:
RMSNorm (Modern LLMs):
Research Insights:
- Pre-Norm: Better gradient flow, used in GPT, LLaMA
- Post-Norm: Original Transformer design, used in BERT
- RMSNorm: 10-50% faster than LayerNorm, equivalent performance
Residual Connections: Gradient Highway
Research Foundation:
- Original Paper: Deep Residual Learning for Image Recognition (He et al., 2015)
- Transformer Application: Attention Is All You Need (Vaswani et al., 2017)
- Gradient Analysis: Understanding the difficulty of training deep feedforward neural networks (Glorot & Bengio, 2010)
- Modern Analysis: Residual Networks Behave Like Ensembles (Veit et al., 2016)
Critical Innovation: Residual connections enable training of very deep networks by providing gradient highways that bypass potential bottlenecks.
Transformer Integration:
Output = LayerNorm(X + Sublayer(X))
where Sublayer ∈ {MultiHeadAttention, FFN}
Mathematical Foundation:
Research Insights:
- Gradient Flow: Enables gradients to flow directly to earlier layers
- Ensemble Behavior: Networks behave like ensembles of shorter paths
- Identity Mapping: Allows layers to learn identity function when needed
- Depth Scaling: Essential for training 100+ layer Transformers
Modern Applications:
- GPT-3: 96 layers with residual connections
- PaLM: 118 layers, residual connections crucial for stability
- Switch Transformer: 2048 layers possible with proper residual design
Positional Encodings: Sequence Order Information
Research Foundation:
- Sinusoidal Encoding: Attention Is All You Need (Vaswani et al., 2017)
- Learned Embeddings: BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018)
- RoPE Innovation: RoFormer: Enhanced Transformer with Rotary Position Embedding (Su et al., 2021)
- ALiBi Method: Train Short, Test Long: Attention with Linear Biases (Press et al., 2021)
- Implementation: RoPE in LLaMA
Critical Challenge: Self-attention is permutation-invariant, requiring explicit position information for sequence understanding.
Evolution of Positional Encoding:
1. Sinusoidal Encoding (2017):
2. Learned Embeddings (2018):
- Trainable position embeddings (BERT, GPT-2)
- Limited to training sequence length
3. Rotary Position Embedding - RoPE (2021):
4. Attention with Linear Biases - ALiBi (2021):
- Adds bias to attention scores: \(\text{softmax}(\mathbf{q}_i^T \mathbf{k}_j + m \cdot |i-j|)\)
Modern Applications:
- GPT-3/4: Learned positional embeddings
- LLaMA: RoPE for better length extrapolation
- PaLM: RoPE with improved scaling
- Mistral: Sliding window + RoPE
Research Insights:
- Length Extrapolation: RoPE and ALiBi handle longer sequences than training
- Efficiency: ALiBi requires no additional parameters
- Performance: RoPE shows superior results on many tasks
Transformer Architecture
Transformers are flexible architectures that fall into three broad categories:
- Encoder-only models — e.g., BERT, RoBERTa
- Decoder-only models — e.g., GPT, LLaMA
- Encoder-Decoder (seq2seq) models — e.g., T5, BART, Whisper
Each architecture is optimized for different tasks: classification, generation, or both.
🏗️ Transformer Architectures: Three Paradigms
🧠 Encoder-Only Models: Bidirectional Understanding
Research Foundation:
- BERT Paper: BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018)
- RoBERTa: RoBERTa: A Robustly Optimized BERT Pretraining Approach (Liu et al., 2019)
- ELECTRA: ELECTRA: Pre-training Text Encoders as Discriminators (Clark et al., 2020)
- Implementation: HuggingFace BERT
Core Innovation: Bidirectional context understanding through masked language modeling, revolutionizing NLP understanding tasks.
┌─────────────────────────────────────────┐
│ Encoder-Only Architecture │
├─────────────────────────────────────────┤
│ [CLS] The cat sat on [MASK] mat [SEP] │
│ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ │
│ Bidirectional Attention │
│ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ │
│ Feed Forward Network │
│ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ │
│ Classification Head │
└─────────────────────────────────────────┘
Research Breakthroughs:
- Masked Language Modeling (MLM): Predicts 15% masked tokens using bidirectional context
- Next Sentence Prediction (NSP): Learns sentence relationships (later found less critical)
- Dynamic Masking: RoBERTa's improvement over static masking
- Replaced Token Detection: ELECTRA's more efficient pre-training objective
Key Model Evolution:
- BERT-Base: 110M parameters, 12 layers, 768 hidden size
- BERT-Large: 340M parameters, 24 layers, 1024 hidden size
- RoBERTa: Removes NSP, uses dynamic masking, larger batches
- DistilBERT: 66M parameters, 97% BERT performance via knowledge distillation
- ELECTRA: 15x more efficient pre-training than BERT
Modern Applications:
- Sentence Classification: GLUE, SuperGLUE benchmarks
- Question Answering: SQuAD, Natural Questions
- Named Entity Recognition: CoNLL-2003, OntoNotes
- Semantic Search: Sentence embeddings, retrieval systems
🧠 Decoder-Only Models: Autoregressive Generation
Research Foundation:
- GPT Paper: Improving Language Understanding by Generative Pre-Training (Radford et al., 2018)
- GPT-2: Language Models are Unsupervised Multitask Learners (Radford et al., 2019)
- GPT-3: Language Models are Few-Shot Learners (Brown et al., 2020)
- LLaMA: LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023)
- Implementation: GPT-2 Implementation
Paradigm Shift: From understanding to generation - autoregressive modeling enables emergent capabilities at scale.
┌─────────────────────────────────────────┐
│ Decoder-Only Architecture │
├─────────────────────────────────────────┤
│ The cat sat on the → [PREDICT] │
│ ↓ ↓ ↓ ↓ ↓ │
│ Causal Attention │
│ (Lower Triangular Mask) │
│ ↓ ↓ ↓ ↓ ↓ │
│ Feed Forward Network │
│ ↓ ↓ ↓ ↓ ↓ │
│ Language Modeling Head │
│ ↓ │
│ "mat" (Next Token) │
└─────────────────────────────────────────┘
Scaling Discoveries:
- Emergent Abilities: Complex reasoning appears at ~100B parameters
- In-Context Learning: Few-shot learning without parameter updates
- Chain-of-Thought: Step-by-step reasoning improves complex tasks
- Instruction Following: Alignment through RLHF and constitutional AI
Architecture Evolution:
- GPT-1: 117M parameters, 12 layers, demonstrates transfer learning
- GPT-2: 1.5B parameters, shows scaling benefits, "too dangerous to release"
- GPT-3: 175B parameters, few-shot learning, emergent capabilities
- LLaMA: Efficient training, RMSNorm, SwiGLU, RoPE innovations
- Mistral: Sliding window attention, mixture of experts
Modern Innovations:
- Mixture of Experts (MoE): Sparse activation for efficient scaling
- Sliding Window Attention: Efficient long-context modeling
- Group Query Attention (GQA): Faster inference with maintained quality
- Constitutional AI: Self-supervised alignment and safety
Research Impact:
- Zero-shot Transfer: Performs tasks without task-specific training
- Code Generation: GitHub Copilot, CodeT5, StarCoder
- Multimodal Extensions: GPT-4V, LLaVA, DALL-E integration
🧠 Encoder-Decoder Models: Sequence Transduction
Research Foundation:
- Original Transformer: Attention Is All You Need (Vaswani et al., 2017)
- T5: Exploring the Limits of Transfer Learning (Raffel et al., 2019)
- BART: Denoising Sequence-to-Sequence Pre-training (Lewis et al., 2019)
- Whisper: Robust Speech Recognition via Large-Scale Weak Supervision (Radford et al., 2022)
- Implementation: T5 Implementation
Architectural Advantage: Combines bidirectional understanding (encoder) with autoregressive generation (decoder) through cross-attention.
┌─────────────────────────────────────────┐
│ Encoder-Decoder Architecture │
├─────────────────────────────────────────┤
│ Input: "Translate: Hello world" │
│ ↓ │
│ ENCODER STACK │
│ (Bidirectional Attention) │
│ ↓ │
│ Encoded Representation │
│ ↓ │
│ DECODER STACK │
│ Self-Attention + Cross-Attention │
│ ↓ │
│ Output: "Bonjour le monde" │
└─────────────────────────────────────────┘
Cross-Attention Innovation:
- Query: From decoder hidden states
- Key/Value: From encoder output representations
- Function: Allows decoder to attend to relevant encoder positions
Pre-training Strategies:
- T5 (Text-to-Text): All tasks as text generation with prefixes
- BART (Denoising): Corrupted input → original text reconstruction
- Whisper (Multimodal): Audio encoder → text decoder
- mT5 (Multilingual): 101 languages with shared vocabulary
Research Breakthroughs:
- Unified Framework: T5 treats all NLP tasks as text-to-text
- Denoising Objectives: BART's span corruption and sentence permutation
- Multimodal Extension: Audio, vision, and text in unified architecture
- Cross-lingual Transfer: mT5's zero-shot cross-lingual capabilities
Modern Applications:
- Machine Translation: WMT benchmarks, commercial translation systems
- Text Summarization: CNN/DailyMail, XSum, scientific paper summarization
- Speech Recognition: Whisper's multilingual ASR capabilities
- Code Generation: CodeT5 for code summarization and generation
Performance Characteristics:
- BLEU Scores: State-of-the-art on translation benchmarks
- ROUGE Scores: Leading summarization performance
- WER (Word Error Rate): Whisper's robust speech recognition
🔁 Architectural Comparison & Research Analysis
Comprehensive Architecture Comparison
| Architecture | Attention Pattern | Parameters | Training Objective | Strengths | Limitations |
|---|---|---|---|---|---|
| Encoder-Only | Bidirectional | 110M-340M (BERT) | Masked LM + NSP | Deep understanding, bidirectional context | No generation capability |
| Decoder-Only | Causal (Autoregressive) | 117M-175B+ (GPT) | Next Token Prediction | Emergent abilities, in-context learning | No bidirectional context |
| Encoder-Decoder | Encoder: Bi, Decoder: Causal | 220M-11B (T5) | Span Corruption/Denoising | Best of both worlds | Higher computational cost |
Performance Benchmarks
Understanding Tasks (GLUE Score):
- BERT-Large: 80.5
- RoBERTa-Large: 88.9
- ELECTRA-Large: 90.9
Generation Tasks (BLEU Score):
- T5-Large: 28.4 (WMT En-De)
- BART-Large: 44.2 (CNN/DM Summarization)
- GPT-3: 25.2 (Few-shot Translation)
Research Insights:
- Scaling Laws: Decoder-only models show better scaling properties
- Transfer Learning: Encoder-only excels at discriminative tasks
- Versatility: Encoder-decoder handles diverse sequence transduction
- Efficiency: Modern decoder-only models achieve comparable understanding with generation capability
📐 Mathematical Formulations
Encoder Layer (Bidirectional Processing):
Decoder Layer (Causal + Cross-Attention):
Attention Mask Patterns:
- Bidirectional: \(\mathbf{M}_{ij} = 0\) (all positions visible)
- Causal: \(\mathbf{M}_{ij} = -\infty\) if \(i < j\) (future masking)
- Padding: \(\mathbf{M}_{ij} = -\infty\) for padding tokens
Cross-Attention Mechanism:
💻 Implementation References
Architecture Implementations:
- Encoder-Only: BERT Implementation →
- Decoder-Only: GPT-2 Implementation →
- Encoder-Decoder: T5 Implementation →
Key Implementation Details:
- Pre-Norm vs Post-Norm: Modern models use Pre-Norm for better gradient flow
- Attention Patterns: Efficient implementations use Flash Attention
- Memory Optimization: Gradient checkpointing for large models
- Parallelization: Model parallelism for multi-GPU training
Training Frameworks:
- HuggingFace Transformers: Training Scripts →
- Megatron-LM: Large Scale Training →
- DeepSpeed: Efficient Training →
🔮 Future Research Directions
Research Frontiers
The Transformer landscape continues evolving rapidly. Here are the most promising directions shaping the next generation of architectures.
🚀 Emerging Architectures
| Architecture | Key Innovation | Scaling Properties | Research Status |
|---|---|---|---|
| Mamba/SSM | Linear attention complexity | \(O(n)\) vs \(O(n^2)\) | Active research |
| Mixture of Experts | Sparse activation | Constant compute per token | Production ready |
| Retrieval-Augmented | External knowledge | Scalable knowledge base | Rapidly advancing |
| Multimodal Unified | Cross-modal attention | Unified architecture | Early adoption |
⚡ Optimization Frontiers
Memory & Compute Efficiency:
- Flash Attention 2.0: Implementation →
- Ring Attention: Distributed attention for infinite context
- Quantization Techniques: INT8/INT4 without quality degradation
Training Innovations:
- Gradient Checkpointing: Memory-efficient backpropagation
- Mixed Precision: FP16/BF16 training acceleration
- Model Parallelism: Scaling beyond single GPU limits
Deployment Optimizations:
- Knowledge Distillation: Compact models from large teachers
- Pruning & Sparsity: Structured model compression
- Edge Deployment: Mobile and IoT optimizations
📖 Additional Resources
Further Learning
- Advanced Techniques: Transformer Advanced Guide
- Architecture Evolution: GPT Evolution Tutorial
- Implementation Practice: HuggingFace Course
- Research Papers: Papers With Code - Transformers
Community & Updates:
- Research Discussions: r/MachineLearning
- Implementation Examples: Annotated Transformer
- Latest Developments: Transformer Circuits Thread
Last updated: January 2024 | Next review: March 2024